Super-Convergence Learning Rate Schedule (TensorFlow Backend)¶
[Paper] [Notebook] [TF Implementation] [Torch Implementation]
In this example we will implement super-convergence learning rate (LR) schedule and test it on a CIFAR10 image classification task. Super-covergence is a phenomenon where neural networks can be trained an order of magnitude faster than with standard training methods. The paper proposes a LR schedule which incorporates two parts: a LR range test to find the appropriate LR range and a cyclical LR schedule that uses the obtained information.
import tempfile
import fastestimator as fe
from fastestimator.architecture.tensorflow import ResNet9
from fastestimator.dataset.data.cifair10 import load_data
from fastestimator.op.numpyop.meta import Sometimes
from fastestimator.op.numpyop.multivariate import HorizontalFlip, PadIfNeeded, RandomCrop
from fastestimator.op.numpyop.univariate import CoarseDropout, Normalize, Onehot
from fastestimator.op.tensorop.loss import CrossEntropy
from fastestimator.op.tensorop.model import ModelOp, UpdateOp
from fastestimator.trace.adapt import LRScheduler
from fastestimator.trace.io import BestModelSaver
from fastestimator.trace.metric import Accuracy
from fastestimator.util import Suppressor
import matplotlib.pyplot as plt
# Parameters
epochs=24
batch_size=128
lr_epochs=100
train_steps_per_epoch=None
save_dir=tempfile.mkdtemp()
Network Architecture and Data Pipeline¶
We will use almost the same image classification configuration of the other Apphub example: CIFAR10 Fast including network architecture and data pipeline. The only difference is that we use SGD optimizer instead of Adam because author of the paper specially pointed out the incompatibility between Adam optimizer and super-convergence.
# prepare dataset
train_data, test_data = load_data()
pipeline = fe.Pipeline(
train_data=train_data,
eval_data=test_data,
batch_size=batch_size,
ops=[
Normalize(inputs="x", outputs="x", mean=(0.4914, 0.4822, 0.4465), std=(0.2471, 0.2435, 0.2616)),
PadIfNeeded(min_height=40, min_width=40, image_in="x", image_out="x", mode="train"),
RandomCrop(32, 32, image_in="x", image_out="x", mode="train"),
Sometimes(HorizontalFlip(image_in="x", image_out="x", mode="train")),
CoarseDropout(inputs="x", outputs="x", mode="train", max_holes=1),
Onehot(inputs="y", outputs="y", mode="train", num_classes=10, label_smoothing=0.2)
])
# prepare network
model = fe.build(model_fn=ResNet9, optimizer_fn="sgd")
network = fe.Network(ops=[
ModelOp(model=model, inputs="x", outputs="y_pred"),
CrossEntropy(inputs=("y_pred", "y"), outputs="ce"),
UpdateOp(model=model, loss_name="ce")
])
LR Range Test¶
The preparation of the super-convergence schedule is to search the suitable LR range. The process is training the target network with a linearly increasing LR and observing the validation accuracy. Generally, the accuracy will keep increase until at some certain point when the LR get too high and start making training diverge. The very LR of that moment is the "maximum LR".
To run the test we need to implement the trace to record the maximum LR. After running the training with linear increaseing LR, we will get the maximum LR.

[The typical learning rate and metircs plot from https://arxiv.org/pdf/1708.07120.pdf]
def linear_increase(step, min_lr=0.0, max_lr=6.0, num_steps=1000):
lr = step / num_steps * (max_lr - min_lr) + min_lr
return lr
traces = [
Accuracy(true_key="y", pred_key="y_pred"),
LRScheduler(model=model, lr_fn=lambda step: linear_increase(step))
]
# prepare estimator
LR_range_test = fe.Estimator(pipeline=pipeline,
network=network,
epochs=lr_epochs,
traces=traces,
train_steps_per_epoch=10,
log_steps=10)
# run the LR_range_test this
print("Running LR range testing... It will take a while")
with Suppressor():
summary = LR_range_test.fit("LR_range_test")
Running LR range testing... It will take a while
Let's plot the accuracy vs LR graph and see the maximum LR.
acc_steps = [step for step in summary.history["eval"]["accuracy"].keys()]
acc_values = [acc for acc in summary.history["eval"]["accuracy"].values()]
best_step, best_acc = max(summary.history["eval"]["accuracy"].items(), key=lambda k: k[1])
lr_max = summary.history["train"]["model_lr"][best_step]
lr_values = [summary.history["train"]["model_lr"][x] for x in acc_steps]
assert len(lr_values) == len(acc_values)
plt.plot(lr_values, acc_values)
plt.plot(lr_max,
best_acc,
'o',
color='r',
label="Best Acc={}, LR={}".format(best_acc, lr_max))
plt.xlabel("Learning Rate")
plt.ylabel("Evaluation Accuracy")
plt.legend(loc='upper left', frameon=False)
<matplotlib.legend.Legend at 0x7f08f4121da0>

Super-Convergence LR Schedule¶
Once we get the maximum LR, the minimum LR can be computed by dividing it by 40. Although this number is set to 4 in the paragraph of the original paper, it falls in range of [4, 40] in its experiment section. We empirically found 40 is the best value for this task.
The LR change has 3 phases:
- increase LR from minimum LR to maximum LR at 0~45% of training process
- decrase LR from maximum LR to minimum LR at 45%~90% of training process
- decrase LR from minimum LR to 0 at 90%~100% of training process
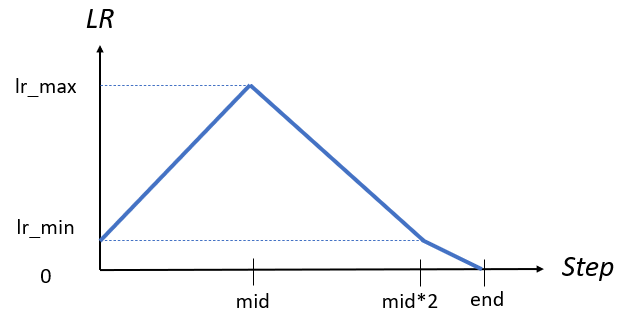
lr_min = lr_max / 40
mid = int(epochs * 0.45 * len(train_data) / batch_size)
end = int(epochs * len(train_data) / batch_size)
def super_schedule(step):
if step < mid:
lr = step / mid * (lr_max - lr_min) + lr_min # linear increase from lr_min to lr_max
elif mid <= step < mid * 2:
lr = lr_max - (step - mid) / mid * (lr_max - lr_min) # linear decrease from lr_max to lr_min
else:
lr = max(lr_min - (step - 2 * mid) / (end - 2 * mid) * lr_min, 0) # linear decrease from lr_min to 0
return lr
Before we start the main training, the model needs to be reinitialized. Therefore we re-instantiate the same network and plug the new LR scheduler in the estimator.
# reinitialize the model
model = fe.build(model_fn=ResNet9, optimizer_fn="sgd")
network = fe.Network(ops=[
ModelOp(model=model, inputs="x", outputs="y_pred"),
CrossEntropy(inputs=("y_pred", "y"), outputs="ce"),
UpdateOp(model=model, loss_name="ce")
])
traces = [
Accuracy(true_key="y", pred_key="y_pred"),
BestModelSaver(model=model, save_dir=save_dir, metric="accuracy", save_best_mode="max"),
LRScheduler(model=model, lr_fn=lambda step: super_schedule(step))
]
# prepare estimator
main_train = fe.Estimator(pipeline=pipeline,
network=network,
epochs=epochs,
traces=traces,
train_steps_per_epoch=train_steps_per_epoch)
main_train.fit()
______ __ ______ __ _ __
/ ____/___ ______/ /_/ ____/____/ /_(_)___ ___ ____ _/ /_____ _____
/ /_ / __ `/ ___/ __/ __/ / ___/ __/ / __ `__ \/ __ `/ __/ __ \/ ___/
/ __/ / /_/ (__ ) /_/ /___(__ ) /_/ / / / / / / /_/ / /_/ /_/ / /
/_/ \__,_/____/\__/_____/____/\__/_/_/ /_/ /_/\__,_/\__/\____/_/
FastEstimator-Start: step: 1; logging_interval: 100; num_device: 1;
FastEstimator-Train: step: 1; ce: 5.776663; model1_lr: 0.10142923;
FastEstimator-Train: step: 100; ce: 4.7230773; model1_lr: 0.19342318; steps/sec: 33.37;
FastEstimator-Train: step: 200; ce: 5.80881; model1_lr: 0.28634638; steps/sec: 33.49;
FastEstimator-Train: step: 300; ce: 2.3463163; model1_lr: 0.37926957; steps/sec: 33.87;
FastEstimator-Train: step: 391; epoch: 1; epoch_time: 12.47 sec;
FastEstimator-BestModelSaver: Saved model to /tmp/tmp9s08iyos/model1_best_accuracy.h5
FastEstimator-Eval: step: 391; epoch: 1; accuracy: 0.4008; ce: 1.7539872; max_accuracy: 0.4008; since_best_accuracy: 0;
FastEstimator-Train: step: 400; ce: 2.0435948; model1_lr: 0.47219273; steps/sec: 28.48;
FastEstimator-Train: step: 500; ce: 1.8763064; model1_lr: 0.5651159; steps/sec: 33.02;
FastEstimator-Train: step: 600; ce: 1.8691326; model1_lr: 0.6580391; steps/sec: 33.46;
FastEstimator-Train: step: 700; ce: 1.7711973; model1_lr: 0.7509623; steps/sec: 33.59;
FastEstimator-Train: step: 782; epoch: 2; epoch_time: 11.77 sec;
FastEstimator-BestModelSaver: Saved model to /tmp/tmp9s08iyos/model1_best_accuracy.h5
FastEstimator-Eval: step: 782; epoch: 2; accuracy: 0.5117; ce: 1.3814019; max_accuracy: 0.5117; since_best_accuracy: 0;
FastEstimator-Train: step: 800; ce: 1.7517064; model1_lr: 0.8438855; steps/sec: 32.87;
FastEstimator-Train: step: 900; ce: 1.7174997; model1_lr: 0.93680865; steps/sec: 33.38;
FastEstimator-Train: step: 1000; ce: 1.684868; model1_lr: 1.0297319; steps/sec: 33.42;
FastEstimator-Train: step: 1100; ce: 1.7329108; model1_lr: 1.122655; steps/sec: 33.62;
FastEstimator-Train: step: 1173; epoch: 3; epoch_time: 11.75 sec;
FastEstimator-BestModelSaver: Saved model to /tmp/tmp9s08iyos/model1_best_accuracy.h5
FastEstimator-Eval: step: 1173; epoch: 3; accuracy: 0.5604; ce: 1.2900568; max_accuracy: 0.5604; since_best_accuracy: 0;
FastEstimator-Train: step: 1200; ce: 1.4787366; model1_lr: 1.2155782; steps/sec: 32.36;
FastEstimator-Train: step: 1300; ce: 1.54497; model1_lr: 1.3085014; steps/sec: 33.81;
FastEstimator-Train: step: 1400; ce: 1.482827; model1_lr: 1.4014246; steps/sec: 33.83;
FastEstimator-Train: step: 1500; ce: 1.4375826; model1_lr: 1.4943478; steps/sec: 33.86;
FastEstimator-Train: step: 1564; epoch: 4; epoch_time: 11.69 sec;
FastEstimator-BestModelSaver: Saved model to /tmp/tmp9s08iyos/model1_best_accuracy.h5
FastEstimator-Eval: step: 1564; epoch: 4; accuracy: 0.6218; ce: 1.1329432; max_accuracy: 0.6218; since_best_accuracy: 0;
FastEstimator-Train: step: 1600; ce: 1.481755; model1_lr: 1.587271; steps/sec: 32.33;
FastEstimator-Train: step: 1700; ce: 1.3139637; model1_lr: 1.6801941; steps/sec: 33.68;
FastEstimator-Train: step: 1800; ce: 1.41434; model1_lr: 1.7731173; steps/sec: 33.81;
FastEstimator-Train: step: 1900; ce: 1.3996168; model1_lr: 1.8660406; steps/sec: 33.85;
FastEstimator-Train: step: 1955; epoch: 5; epoch_time: 11.68 sec;
FastEstimator-BestModelSaver: Saved model to /tmp/tmp9s08iyos/model1_best_accuracy.h5
FastEstimator-Eval: step: 1955; epoch: 5; accuracy: 0.6826; ce: 0.99024403; max_accuracy: 0.6826; since_best_accuracy: 0;
FastEstimator-Train: step: 2000; ce: 1.3781737; model1_lr: 1.9589638; steps/sec: 32.92;
FastEstimator-Train: step: 2100; ce: 1.3097632; model1_lr: 2.0518868; steps/sec: 33.76;
FastEstimator-Train: step: 2200; ce: 1.2388372; model1_lr: 2.1448102; steps/sec: 33.82;
FastEstimator-Train: step: 2300; ce: 1.4561124; model1_lr: 2.2377334; steps/sec: 33.74;
FastEstimator-Train: step: 2346; epoch: 6; epoch_time: 11.66 sec;
FastEstimator-Eval: step: 2346; epoch: 6; accuracy: 0.6533; ce: 1.0776143; max_accuracy: 0.6826; since_best_accuracy: 1;
FastEstimator-Train: step: 2400; ce: 1.3061807; model1_lr: 2.3306565; steps/sec: 32.75;
FastEstimator-Train: step: 2500; ce: 1.3196818; model1_lr: 2.4235797; steps/sec: 33.8;
FastEstimator-Train: step: 2600; ce: 1.3396112; model1_lr: 2.5165029; steps/sec: 33.69;
FastEstimator-Train: step: 2700; ce: 1.2553616; model1_lr: 2.609426; steps/sec: 33.71;
FastEstimator-Train: step: 2737; epoch: 7; epoch_time: 11.68 sec;
FastEstimator-Eval: step: 2737; epoch: 7; accuracy: 0.0981; ce: 5.6395764; max_accuracy: 0.6826; since_best_accuracy: 2;
FastEstimator-Train: step: 2800; ce: 2.0294547; model1_lr: 2.7023492; steps/sec: 32.96;
FastEstimator-Train: step: 2900; ce: 1.5744395; model1_lr: 2.7952724; steps/sec: 33.66;
FastEstimator-Train: step: 3000; ce: 1.3871385; model1_lr: 2.8881955; steps/sec: 33.71;
FastEstimator-Train: step: 3100; ce: 1.4019853; model1_lr: 2.9811187; steps/sec: 33.59;
FastEstimator-Train: step: 3128; epoch: 8; epoch_time: 11.71 sec;
FastEstimator-BestModelSaver: Saved model to /tmp/tmp9s08iyos/model1_best_accuracy.h5
FastEstimator-Eval: step: 3128; epoch: 8; accuracy: 0.7834; ce: 0.68519104; max_accuracy: 0.7834; since_best_accuracy: 0;
FastEstimator-Train: step: 3200; ce: 1.377032; model1_lr: 3.0740418; steps/sec: 32.6;
FastEstimator-Train: step: 3300; ce: 1.3246766; model1_lr: 3.1669652; steps/sec: 33.61;
FastEstimator-Train: step: 3400; ce: 1.3278141; model1_lr: 3.2598884; steps/sec: 33.82;
FastEstimator-Train: step: 3500; ce: 1.2375286; model1_lr: 3.3528116; steps/sec: 33.11;
FastEstimator-Train: step: 3519; epoch: 9; epoch_time: 11.72 sec;
FastEstimator-Eval: step: 3519; epoch: 9; accuracy: 0.7133; ce: 0.98150647; max_accuracy: 0.7834; since_best_accuracy: 1;
FastEstimator-Train: step: 3600; ce: 1.2265539; model1_lr: 3.4457347; steps/sec: 32.91;
FastEstimator-Train: step: 3700; ce: 1.4098625; model1_lr: 3.538658; steps/sec: 33.76;
FastEstimator-Train: step: 3800; ce: 1.2486908; model1_lr: 3.631581; steps/sec: 33.77;
FastEstimator-Train: step: 3900; ce: 1.2460911; model1_lr: 3.7245042; steps/sec: 33.43;
FastEstimator-Train: step: 3910; epoch: 10; epoch_time: 11.65 sec;
FastEstimator-Eval: step: 3910; epoch: 10; accuracy: 0.7253; ce: 0.88525856; max_accuracy: 0.7834; since_best_accuracy: 2;
FastEstimator-Train: step: 4000; ce: 1.1750683; model1_lr: 3.8174274; steps/sec: 33.16;
FastEstimator-Train: step: 4100; ce: 1.2834225; model1_lr: 3.9103506; steps/sec: 33.57;
FastEstimator-Train: step: 4200; ce: 1.3357248; model1_lr: 4.003274; steps/sec: 33.72;
FastEstimator-Train: step: 4300; ce: 1.1901045; model1_lr: 3.943803; steps/sec: 33.13;
FastEstimator-Train: step: 4301; epoch: 11; epoch_time: 11.71 sec;
FastEstimator-Eval: step: 4301; epoch: 11; accuracy: 0.7001; ce: 0.9235585; max_accuracy: 0.7834; since_best_accuracy: 3;
FastEstimator-Train: step: 4400; ce: 1.2157128; model1_lr: 3.8508797; steps/sec: 33.24;
FastEstimator-Train: step: 4500; ce: 1.1261709; model1_lr: 3.7579565; steps/sec: 33.79;
FastEstimator-Train: step: 4600; ce: 1.1690426; model1_lr: 3.6650333; steps/sec: 33.69;
FastEstimator-Train: step: 4692; epoch: 12; epoch_time: 11.66 sec;
FastEstimator-BestModelSaver: Saved model to /tmp/tmp9s08iyos/model1_best_accuracy.h5
FastEstimator-Eval: step: 4692; epoch: 12; accuracy: 0.8259; ce: 0.6520777; max_accuracy: 0.8259; since_best_accuracy: 0;
FastEstimator-Train: step: 4700; ce: 1.2337161; model1_lr: 3.5721102; steps/sec: 33.06;
FastEstimator-Train: step: 4800; ce: 1.1818956; model1_lr: 3.479187; steps/sec: 33.77;
FastEstimator-Train: step: 4900; ce: 1.2220985; model1_lr: 3.3862638; steps/sec: 33.78;
FastEstimator-Train: step: 5000; ce: 1.1691927; model1_lr: 3.2933407; steps/sec: 33.64;
FastEstimator-Train: step: 5083; epoch: 13; epoch_time: 11.68 sec;
FastEstimator-BestModelSaver: Saved model to /tmp/tmp9s08iyos/model1_best_accuracy.h5
FastEstimator-Eval: step: 5083; epoch: 13; accuracy: 0.8285; ce: 0.6635361; max_accuracy: 0.8285; since_best_accuracy: 0;
FastEstimator-Train: step: 5100; ce: 1.0983471; model1_lr: 3.2004175; steps/sec: 32.71;
FastEstimator-Train: step: 5200; ce: 1.1542699; model1_lr: 3.1074944; steps/sec: 33.7;
FastEstimator-Train: step: 5300; ce: 1.1538193; model1_lr: 3.0145712; steps/sec: 33.79; FastEstimator-Train: step: 5400; ce: 1.1344184; model1_lr: 2.921648; steps/sec: 33.8; FastEstimator-Train: step: 5474; epoch: 14; epoch_time: 11.67 sec; FastEstimator-BestModelSaver: Saved model to /tmp/tmp9s08iyos/model1_best_accuracy.h5 FastEstimator-Eval: step: 5474; epoch: 14; accuracy: 0.8652; ce: 0.5354095; max_accuracy: 0.8652; since_best_accuracy: 0; FastEstimator-Train: step: 5500; ce: 1.0998952; model1_lr: 2.8287246; steps/sec: 32.61; FastEstimator-Train: step: 5600; ce: 1.141614; model1_lr: 2.7358015; steps/sec: 33.68; FastEstimator-Train: step: 5700; ce: 1.1103913; model1_lr: 2.6428783; steps/sec: 33.8; FastEstimator-Train: step: 5800; ce: 1.1439428; model1_lr: 2.5499551; steps/sec: 33.66; FastEstimator-Train: step: 5865; epoch: 15; epoch_time: 11.72 sec; FastEstimator-Eval: step: 5865; epoch: 15; accuracy: 0.8397; ce: 0.64034617; max_accuracy: 0.8652; since_best_accuracy: 1; FastEstimator-Train: step: 5900; ce: 1.1166975; model1_lr: 2.457032; steps/sec: 32.52; FastEstimator-Train: step: 6000; ce: 1.0917354; model1_lr: 2.3641088; steps/sec: 33.79; FastEstimator-Train: step: 6100; ce: 1.079163; model1_lr: 2.2711856; steps/sec: 33.72; FastEstimator-Train: step: 6200; ce: 1.07494; model1_lr: 2.1782625; steps/sec: 33.61; FastEstimator-Train: step: 6256; epoch: 16; epoch_time: 11.68 sec; FastEstimator-Eval: step: 6256; epoch: 16; accuracy: 0.8358; ce: 0.6846055; max_accuracy: 0.8652; since_best_accuracy: 2; FastEstimator-Train: step: 6300; ce: 1.073894; model1_lr: 2.0853393; steps/sec: 32.93; FastEstimator-Train: step: 6400; ce: 1.0491798; model1_lr: 1.992416; steps/sec: 33.59; FastEstimator-Train: step: 6500; ce: 1.1131084; model1_lr: 1.8994929; steps/sec: 33.54; FastEstimator-Train: step: 6600; ce: 1.0556369; model1_lr: 1.8065697; steps/sec: 33.39; FastEstimator-Train: step: 6647; epoch: 17; epoch_time: 11.72 sec; FastEstimator-BestModelSaver: Saved model to /tmp/tmp9s08iyos/model1_best_accuracy.h5 FastEstimator-Eval: step: 6647; epoch: 17; accuracy: 0.8826; ce: 0.5354589; max_accuracy: 0.8826; since_best_accuracy: 0; FastEstimator-Train: step: 6700; ce: 1.041785; model1_lr: 1.7136465; steps/sec: 32.93; FastEstimator-Train: step: 6800; ce: 1.0919912; model1_lr: 1.6207234; steps/sec: 33.66; FastEstimator-Train: step: 6900; ce: 1.0730321; model1_lr: 1.5278001; steps/sec: 33.58; FastEstimator-Train: step: 7000; ce: 1.0604472; model1_lr: 1.4348769; steps/sec: 33.76; FastEstimator-Train: step: 7038; epoch: 18; epoch_time: 11.7 sec; FastEstimator-BestModelSaver: Saved model to /tmp/tmp9s08iyos/model1_best_accuracy.h5 FastEstimator-Eval: step: 7038; epoch: 18; accuracy: 0.8927; ce: 0.4799063; max_accuracy: 0.8927; since_best_accuracy: 0; FastEstimator-Train: step: 7100; ce: 1.0326926; model1_lr: 1.3419538; steps/sec: 32.7; FastEstimator-Train: step: 7200; ce: 1.0019332; model1_lr: 1.2490306; steps/sec: 33.74; FastEstimator-Train: step: 7300; ce: 1.0385857; model1_lr: 1.1561074; steps/sec: 33.59; FastEstimator-Train: step: 7400; ce: 1.0323408; model1_lr: 1.0631843; steps/sec: 33.19; FastEstimator-Train: step: 7429; epoch: 19; epoch_time: 11.77 sec; FastEstimator-BestModelSaver: Saved model to /tmp/tmp9s08iyos/model1_best_accuracy.h5 FastEstimator-Eval: step: 7429; epoch: 19; accuracy: 0.898; ce: 0.45474234; max_accuracy: 0.898; since_best_accuracy: 0; FastEstimator-Train: step: 7500; ce: 1.0034448; model1_lr: 0.97026104; steps/sec: 31.99; FastEstimator-Train: step: 7600; ce: 1.0002831; model1_lr: 0.8773378; steps/sec: 33.4; FastEstimator-Train: step: 7700; ce: 0.9859823; model1_lr: 0.78441465; steps/sec: 32.05; FastEstimator-Train: step: 7800; ce: 1.0219489; model1_lr: 0.6914915; steps/sec: 33.25; FastEstimator-Train: step: 7820; epoch: 20; epoch_time: 11.94 sec; FastEstimator-BestModelSaver: Saved model to /tmp/tmp9s08iyos/model1_best_accuracy.h5 FastEstimator-Eval: step: 7820; epoch: 20; accuracy: 0.9061; ce: 0.43634492; max_accuracy: 0.9061; since_best_accuracy: 0; FastEstimator-Train: step: 7900; ce: 0.9971979; model1_lr: 0.59856826; steps/sec: 32.97; FastEstimator-Train: step: 8000; ce: 0.987967; model1_lr: 0.5056451; steps/sec: 33.69; FastEstimator-Train: step: 8100; ce: 1.0111182; model1_lr: 0.4127219; steps/sec: 33.83; FastEstimator-Train: step: 8200; ce: 1.0593884; model1_lr: 0.3197987; steps/sec: 33.23; FastEstimator-Train: step: 8211; epoch: 21; epoch_time: 11.69 sec; FastEstimator-BestModelSaver: Saved model to /tmp/tmp9s08iyos/model1_best_accuracy.h5 FastEstimator-Eval: step: 8211; epoch: 21; accuracy: 0.9065; ce: 0.4418834; max_accuracy: 0.9065; since_best_accuracy: 0; FastEstimator-Train: step: 8300; ce: 0.9793607; model1_lr: 0.22687553; steps/sec: 32.46; FastEstimator-Train: step: 8400; ce: 0.97971845; model1_lr: 0.13395235; steps/sec: 31.46; FastEstimator-Train: step: 8500; ce: 1.0591702; model1_lr: 0.09365016; steps/sec: 33.74; FastEstimator-Train: step: 8600; ce: 1.0542408; model1_lr: 0.082947284; steps/sec: 32.67; FastEstimator-Train: step: 8602; epoch: 22; epoch_time: 11.97 sec; FastEstimator-BestModelSaver: Saved model to /tmp/tmp9s08iyos/model1_best_accuracy.h5 FastEstimator-Eval: step: 8602; epoch: 22; accuracy: 0.9074; ce: 0.43536025; max_accuracy: 0.9074; since_best_accuracy: 0; FastEstimator-Train: step: 8700; ce: 0.98823214; model1_lr: 0.072244406; steps/sec: 33.52; FastEstimator-Train: step: 8800; ce: 0.97655475; model1_lr: 0.061541535; steps/sec: 33.76; FastEstimator-Train: step: 8900; ce: 0.95179796; model1_lr: 0.050838657; steps/sec: 33.69; FastEstimator-Train: step: 8993; epoch: 23; epoch_time: 11.68 sec; FastEstimator-BestModelSaver: Saved model to /tmp/tmp9s08iyos/model1_best_accuracy.h5 FastEstimator-Eval: step: 8993; epoch: 23; accuracy: 0.9106; ce: 0.43370104; max_accuracy: 0.9106; since_best_accuracy: 0; FastEstimator-Train: step: 9000; ce: 0.99330795; model1_lr: 0.040135782; steps/sec: 32.76; FastEstimator-Train: step: 9100; ce: 0.96883345; model1_lr: 0.029432908; steps/sec: 33.6; FastEstimator-Train: step: 9200; ce: 1.012826; model1_lr: 0.018730031; steps/sec: 33.8; FastEstimator-Train: step: 9300; ce: 1.0013785; model1_lr: 0.008027157; steps/sec: 33.65; FastEstimator-Train: step: 9384; epoch: 24; epoch_time: 11.7 sec; FastEstimator-Eval: step: 9384; epoch: 24; accuracy: 0.9093; ce: 0.4368044; max_accuracy: 0.9106; since_best_accuracy: 1; FastEstimator-Finish: step: 9384; model1_lr: 0.0; total_time: 321.15 sec;
Result Discussion¶
The result of it might not be super impressive when comparing with original example CIFAR10 Fast. But please be aware that the example has its own LR schedules which is specially tuned on that configuration (plus that scheduler is also cyclical LR schedule).