Semantic segmentation using Line Search¶
[Paper] [Notebook] [TF Implementation] [Torch Implementation]
In this example, we are going to implement an idea similar to "Bounding Box Tightness Prior for Weakly Supervised Image Segmentation" in Tensorflow.
The core idea of the paper is to perform semantic segmentation while using only bounding box as a ground truth. The paper uses multiple instance learning(MIL) to create positive and negative bags of samples using the bounding box. In MIL, a bag is labeled as negative if all of its samples are negative and a bag is positive if it has at least one sample which is positive. For semantic segmenation using bounding box, authors propose that we consider the lines passing through bounding box as positive bags and all other lines as negative. As shown in the following image, the green and yellow lines are considered to be positive and blue lines are considered to be negative for a particular category.

Here we are implementing a simplified approach inspired by the Paper. Instead of selecting these positive and negative lines from the image prediction, we perform a max operation over all the axes individually which results in a 1D vector per axis called prediction vectors. Similar to the parent paper we assume that we have accurate bounding box information for each object in the image. We convert these bounding box co-ordinates into binary masks for each object. Once we have these binary masks, we again perform a max operation over all the axes individually which results in a 1D vector per axis called bounding-box vectors. These bounding-box vectors per object acts as our ground truth for an object. Once we have prepared the prediction vectors and the bounding-box vector for each object, we can use Binary Cross-Entropy as a loss function.
Importing Libraries¶
import tempfile
import cv2
import numpy as np
import tensorflow as tf
from skimage import measure
import fastestimator as fe
from fastestimator.architecture.tensorflow import UNet
from fastestimator.dataset.data import montgomery
from fastestimator.op.numpyop import Delete
from fastestimator.op.numpyop import LambdaOp as NLambdaOp
from fastestimator.op.numpyop.meta import Sometimes
from fastestimator.op.numpyop.multivariate import Resize, Rotate
from fastestimator.op.numpyop.univariate import Minmax, ReadImage, Binarize
from fastestimator.op.tensorop import LambdaOp
from fastestimator.op.tensorop.loss import CrossEntropy
from fastestimator.op.tensorop.model import ModelOp, UpdateOp
from fastestimator.trace.io import BestModelSaver
from fastestimator.trace.metric import Dice
from fastestimator.util import BatchDisplay, GridDisplay
# training_parameters
epochs=20
batch_size=8
train_steps_per_epoch = 500
eval_steps_per_epoch = None
save_dir=tempfile.mkdtemp()
data_dir=None
im_size = 512
line_degree = 45
csv_dataset = montgomery.load_data(root_dir=data_dir)
Customized Ops¶
Since our aim is to use bounding boxes to predict the pixel wise segmentation mask, let us generate a 2D binary mask consisting only the bounding box of the lungs using the pixel wise ground truth available
class BoundingBoxMask(fe.op.numpyop.NumpyOp):
"""Converting Pixel Level Binary Mask to a Bounding Box binary mask.
Bounding box coordinates are calculated using the Pixel level binary mask. These coordinates are then used to
create a Binary mask of Bounding Boxes.
Args:
inputs: Key(s) of masks to be combined.
outputs: Key(s) into which to write the combined masks.
mode: What mode(s) to execute this Op in. For example, "train", "eval", "test", or "infer".
"""
def forward(self, data, state):
y_true = data
mask = np.zeros_like(y_true)
blobs, n_blob = measure.label(y_true[:, :, 0], background=0, return_num=True)
for b in range(1, n_blob + 1):
blob_mask = blobs == b
coords = np.argwhere(blob_mask)
x1, y1 = coords.min(axis=0)
x2, y2 = coords.max(axis=0)
box = [y1, x1, y2, x2]
mask[box[1]:box[3] + 1, box[0]:box[2] + 1, 0] = 1
return mask
Set up the preprocessing Pipline¶
In this example, the data preprocessing steps include Merging masks into one dimension, expanding image dimension, rotating the image and mask at a random angle, normalizing the image pixel values to the range [0, 1], and binarizing pixel values. We set up these processing steps using Ops, while also defining the data source and batch size for the Pipeline.
NOTE : To generate Bounding Box mask, it is necessary for input mask to be Binarized. Therefore, we make sure to binarize the pixel-wise mask before building bounding-box based mask.
Here, we use rotation as a preprocessing step to extract positive bags at a random angle in the later steps. Also, the BoundingBoxFromMask Op is used to extract bounding box based binary masks from the actual ground truth.
pipeline = fe.Pipeline(
train_data=csv_dataset,
eval_data=csv_dataset.split(0.2),
batch_size=batch_size,
ops=[
ReadImage(inputs="image", parent_path=csv_dataset.parent_path, outputs="image", color_flag='gray'),
ReadImage(inputs="mask_left", parent_path=csv_dataset.parent_path, outputs="mask_left", color_flag='gray'),
ReadImage(inputs="mask_right", parent_path=csv_dataset.parent_path, outputs="mask_right", color_flag='gray'),
NLambdaOp(fn=lambda x, y: np.maximum(x, y), inputs=("mask_left", "mask_right"), outputs="mask"),
Resize(image_in="image", width=im_size, height=im_size),
Resize(image_in="mask", width=im_size, height=im_size),
Sometimes(numpy_op=Rotate(image_in="image",
mask_in="mask",
limit=(-line_degree, line_degree),
border_mode=cv2.BORDER_CONSTANT,
mode='train')),
Minmax(inputs="image", outputs="image"),
Minmax(inputs="mask", outputs="mask"),
Binarize(inputs="mask", outputs="mask", threshold=0.5),
BoundingBoxMask(inputs="mask", outputs="box_mask"),
Delete(keys=("mask_left", "mask_right"))
])
Validate Pipeline¶
In order to make sure the pipeline works as expected, we need to visualize its output. Pipeline.get_results will return a batch of data for this purpose:
data = pipeline.get_results()
image = data["image"]
mask = data["mask"]
bbox_mask = data['box_mask']
print("the pipeline input image size: {}".format(image.numpy().shape))
print("the pipeline input mask size: {}".format(mask.numpy().shape))
print("the pipeline output bounding box mask size: {}".format(bbox_mask.numpy().shape))
the pipeline input image size: (8, 512, 512, 1) the pipeline input mask size: (8, 512, 512, 1) the pipeline output bounding box mask size: (8, 512, 512, 1)
Let's select 4 samples and visualize the differences between the Pipeline input and output.
sample_num = 4
GridDisplay([BatchDisplay(image=image[0:sample_num], title="Input Image"),
BatchDisplay(image=image[0:sample_num], masks=mask[0:sample_num], title="Input Mask"),
BatchDisplay(image=image[0:sample_num], masks=bbox_mask[0:sample_num], title="Bounding Box Mask")]).show()

model = fe.build(model_fn=lambda: UNet(input_size=(im_size, im_size, 1)),
optimizer_fn=lambda: tf.keras.optimizers.Adam(learning_rate=0.0001))
2023-01-04 22:56:54.253869: I tensorflow/core/platform/cpu_feature_guard.cc:193] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 FMA To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags. 2023-01-04 22:56:54.720739: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1532] Created device /job:localhost/replica:0/task:0/device:GPU:0 with 38418 MB memory: -> device: 0, name: NVIDIA A100-SXM4-40GB, pci bus id: 0000:bd:00.0, compute capability: 8.0
Network Definition¶
Now since we have our pipeline and model ready, we can start building our network and loss functions. First, we need to pick up positive and negative bags from the predicted mask. As we have already discussed, we achieve this by performing a max operation along each axis, which provides us with 1D vectors. When this operation is performed over our Bounding Box binary mask, the 1D vectors look like following. (Figure on LEFT)
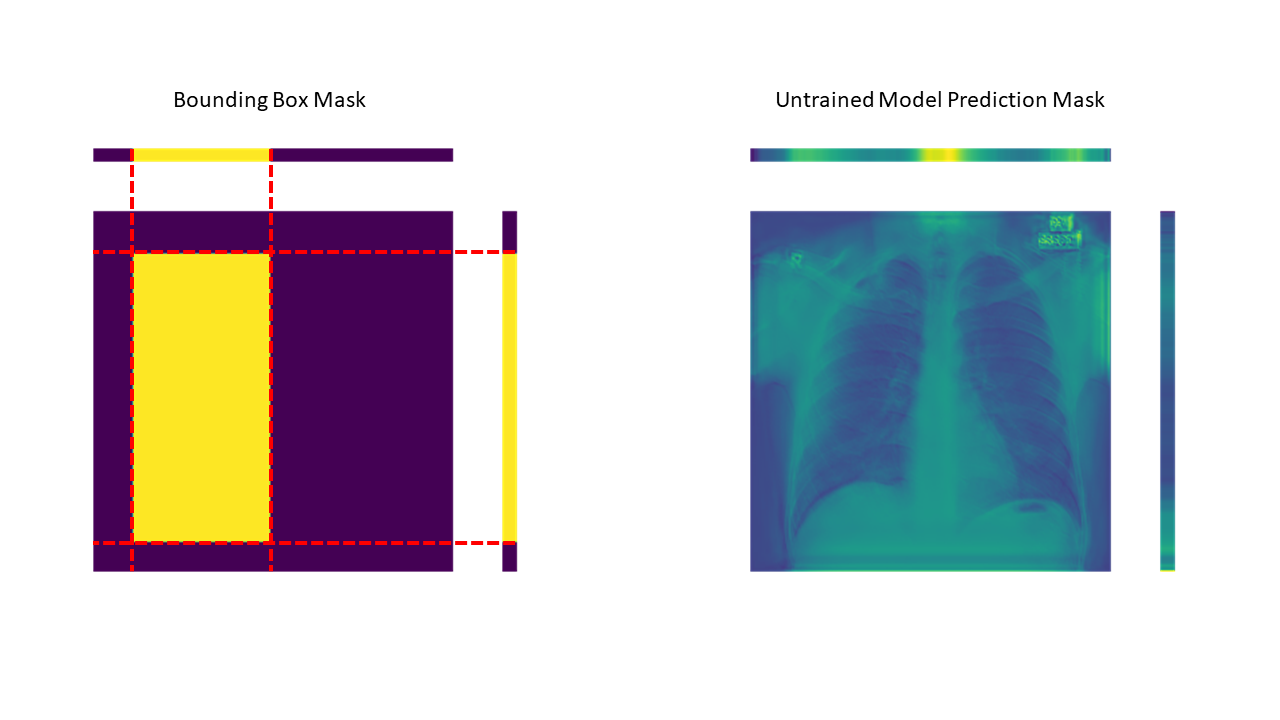
Since the bounding box mask is binarized, the max operation across rows and columns, generates '0' when the lines do not pass through the bounding box and generate '1' when the line passes through the bounding box. By performing this max operation over rows and columns, we indirectly consider each row and column as a bag and if that row or column passes through the bounding box, we assign it to label '1' (positive bag), otherwise it is assigned to label '0' (negative bag).
When the same operation is performed over the prediction of our untrained model, we get the vectors visualized in the figure above. (Figure on RIGHT)
Now, once we have these 1D prediction vectors and Bounding-Box vectors ready, we treat these 1D Bounding-Box vectors as Ground Truth and train our UNET model using Binary Cross Entropy loss per axis.
network = fe.Network(ops=[
ModelOp(inputs="image", model=model, outputs="pred_segment"),
LambdaOp(fn=lambda x: tf.reduce_max(x, axis=1), inputs="pred_segment", outputs="pred_x"),
LambdaOp(fn=lambda x: tf.reduce_max(x, axis=1), inputs="box_mask", outputs="mask_x"),
LambdaOp(fn=lambda x: tf.reduce_max(x, axis=2), inputs="pred_segment", outputs="pred_y"),
LambdaOp(fn=lambda x: tf.reduce_max(x, axis=2), inputs="box_mask", outputs="mask_y"),
CrossEntropy(inputs=("pred_x", "mask_x"), outputs="loss_x", form="binary"),
CrossEntropy(inputs=("pred_y", "mask_y"), outputs="loss_y", form="binary"),
LambdaOp(fn=lambda x, y: x + y, inputs=("loss_x", "loss_y"), outputs="loss", mode="!infer"),
UpdateOp(model=model, loss_name="loss"),
CrossEntropy(inputs=("pred_segment", "mask"), outputs="ce",
form="binary") # To track model performance on a pixel-level mask, this is for monitoring purpose ONLY
])
Step 3 - Estimator definition and training¶
In this step, we define the Estimator to compile the Network and Pipeline and indicate in traces that we want to save the best models. We can then use estimator.fit() to start the training process:
traces = [
Dice(true_key="mask", pred_key="pred_segment"),
BestModelSaver(model=model, save_dir=save_dir, metric='Dice', save_best_mode='max', load_best_final=True)
]
estimator = fe.Estimator(network=network,
pipeline=pipeline,
epochs=epochs,
traces=traces,
train_steps_per_epoch=train_steps_per_epoch,
eval_steps_per_epoch=eval_steps_per_epoch,
monitor_names='ce')
estimator.fit()
______ __ ______ __ _ __
/ ____/___ ______/ /_/ ____/____/ /_(_)___ ___ ____ _/ /_____ _____
/ /_ / __ `/ ___/ __/ __/ / ___/ __/ / __ `__ \/ __ `/ __/ __ \/ ___/
/ __/ / /_/ (__ ) /_/ /___(__ ) /_/ / / / / / / /_/ / /_/ /_/ / /
/_/ \__,_/____/\__/_____/____/\__/_/_/ /_/ /_/\__,_/\__/\____/_/
2023-01-04 22:57:05.650656: I tensorflow/stream_executor/cuda/cuda_dnn.cc:384] Loaded cuDNN version 8100
FastEstimator-Start: step: 1; logging_interval: 100; num_device: 1; FastEstimator-Train: step: 1; ce: 0.7713827; loss: 1.1096117; FastEstimator-Train: step: 100; ce: 0.6885747; loss: 0.54330736; steps/sec: 4.33; FastEstimator-Train: step: 200; ce: 0.45575762; loss: 0.48816502; steps/sec: 4.24; FastEstimator-Train: step: 300; ce: 0.31905615; loss: 0.1888443; steps/sec: 4.23; FastEstimator-Train: step: 400; ce: 0.5192288; loss: 0.2905901; steps/sec: 4.24; FastEstimator-Train: step: 500; ce: 0.21075621; loss: 0.11548169; steps/sec: 4.24; FastEstimator-Train: step: 500; epoch: 1; epoch_time(sec): 129.62; Eval Progress: 1/3; Eval Progress: 2/3; steps/sec: 7.2; Eval Progress: 3/3; steps/sec: 6.74; FastEstimator-BestModelSaver: Saved model to /tmp/tmpvj987yxr/model_best_Dice.h5 FastEstimator-Eval: step: 500; epoch: 1; ce: 0.1540004; Dice: 0.9091099; loss: 0.12604196; max_Dice: 0.9091099; since_best_Dice: 0; FastEstimator-Train: step: 600; ce: 0.14964913; loss: 0.09621328; steps/sec: 3.1; FastEstimator-Train: step: 700; ce: 0.25923535; loss: 0.13143216; steps/sec: 4.24; FastEstimator-Train: step: 800; ce: 0.21946776; loss: 0.07082817; steps/sec: 4.24; FastEstimator-Train: step: 900; ce: 0.15505707; loss: 0.06435156; steps/sec: 4.25; FastEstimator-Train: step: 1000; ce: 0.18911056; loss: 0.04319794; steps/sec: 4.24; FastEstimator-Train: step: 1000; epoch: 2; epoch_time(sec): 126.53; Eval Progress: 1/3; Eval Progress: 2/3; steps/sec: 7.82; Eval Progress: 3/3; steps/sec: 6.8; FastEstimator-BestModelSaver: Saved model to /tmp/tmpvj987yxr/model_best_Dice.h5 FastEstimator-Eval: step: 1000; epoch: 2; ce: 0.13218604; Dice: 0.93149793; loss: 0.08127645; max_Dice: 0.93149793; since_best_Dice: 0; FastEstimator-Train: step: 1100; ce: 0.15152483; loss: 0.0418622; steps/sec: 3.14; FastEstimator-Train: step: 1200; ce: 0.16294584; loss: 0.039804567; steps/sec: 4.24; FastEstimator-Train: step: 1300; ce: 0.17077501; loss: 0.10763016; steps/sec: 4.24; FastEstimator-Train: step: 1400; ce: 0.14382252; loss: 0.044657648; steps/sec: 4.25; FastEstimator-Train: step: 1500; ce: 0.14443177; loss: 0.04706917; steps/sec: 4.23; FastEstimator-Train: step: 1500; epoch: 3; epoch_time(sec): 126.09; Eval Progress: 1/3; Eval Progress: 2/3; steps/sec: 3.5; Eval Progress: 3/3; steps/sec: 7.22; FastEstimator-Eval: step: 1500; epoch: 3; ce: 0.13909817; Dice: 0.9059331; loss: 0.07223539; max_Dice: 0.93149793; since_best_Dice: 1; FastEstimator-Train: step: 1600; ce: 0.12332831; loss: 0.057900418; steps/sec: 3.15; FastEstimator-Train: step: 1700; ce: 0.19545384; loss: 0.029384777; steps/sec: 4.25; FastEstimator-Train: step: 1800; ce: 0.1673477; loss: 0.055532694; steps/sec: 4.24; FastEstimator-Train: step: 1900; ce: 0.11157583; loss: 0.04087561; steps/sec: 4.25; FastEstimator-Train: step: 2000; ce: 0.14402151; loss: 0.05754735; steps/sec: 4.25; FastEstimator-Train: step: 2000; epoch: 4; epoch_time(sec): 125.96; Eval Progress: 1/3; Eval Progress: 2/3; steps/sec: 7.79; Eval Progress: 3/3; steps/sec: 8.37; FastEstimator-BestModelSaver: Saved model to /tmp/tmpvj987yxr/model_best_Dice.h5 FastEstimator-Eval: step: 2000; epoch: 4; ce: 0.08900395; Dice: 0.93875873; loss: 0.08554197; max_Dice: 0.93875873; since_best_Dice: 0; FastEstimator-Train: step: 2100; ce: 0.16995817; loss: 0.03475161; steps/sec: 3.12; FastEstimator-Train: step: 2200; ce: 0.11625035; loss: 0.039744377; steps/sec: 4.24; FastEstimator-Train: step: 2300; ce: 0.11989611; loss: 0.03607356; steps/sec: 4.24; FastEstimator-Train: step: 2400; ce: 0.10687587; loss: 0.040772386; steps/sec: 4.25; FastEstimator-Train: step: 2500; ce: 0.115603045; loss: 0.03607551; steps/sec: 4.25; FastEstimator-Train: step: 2500; epoch: 5; epoch_time(sec): 126.33; Eval Progress: 1/3; Eval Progress: 2/3; steps/sec: 7.8; Eval Progress: 3/3; steps/sec: 8.0; FastEstimator-Eval: step: 2500; epoch: 5; ce: 0.12147838; Dice: 0.9374156; loss: 0.08198957; max_Dice: 0.93875873; since_best_Dice: 1; FastEstimator-Train: step: 2600; ce: 0.14630826; loss: 0.027665494; steps/sec: 3.17; FastEstimator-Train: step: 2700; ce: 0.12917197; loss: 0.025014501; steps/sec: 4.25; FastEstimator-Train: step: 2800; ce: 0.1337129; loss: 0.033332422; steps/sec: 4.26; FastEstimator-Train: step: 2900; ce: 0.11265276; loss: 0.027036026; steps/sec: 4.25; FastEstimator-Train: step: 3000; ce: 0.10444577; loss: 0.025305226; steps/sec: 4.26; FastEstimator-Train: step: 3000; epoch: 6; epoch_time(sec): 125.58; Eval Progress: 1/3; Eval Progress: 2/3; steps/sec: 2.3; Eval Progress: 3/3; steps/sec: 6.39; FastEstimator-BestModelSaver: Saved model to /tmp/tmpvj987yxr/model_best_Dice.h5 FastEstimator-Eval: step: 3000; epoch: 6; ce: 0.10225687; Dice: 0.94388235; loss: 0.0746724; max_Dice: 0.94388235; since_best_Dice: 0; FastEstimator-Train: step: 3100; ce: 0.109292254; loss: 0.028109007; steps/sec: 3.13; FastEstimator-Train: step: 3200; ce: 0.1476033; loss: 0.035841204; steps/sec: 4.25; FastEstimator-Train: step: 3300; ce: 0.1314058; loss: 0.034800984; steps/sec: 4.25; FastEstimator-Train: step: 3400; ce: 0.13723981; loss: 0.028775714; steps/sec: 4.25; FastEstimator-Train: step: 3500; ce: 0.14512397; loss: 0.029680304; steps/sec: 4.25; FastEstimator-Train: step: 3500; epoch: 7; epoch_time(sec): 126.1; Eval Progress: 1/3; Eval Progress: 2/3; steps/sec: 9.68; Eval Progress: 3/3; steps/sec: 8.1; FastEstimator-Eval: step: 3500; epoch: 7; ce: 0.12283552; Dice: 0.9412691; loss: 0.075770035; max_Dice: 0.94388235; since_best_Dice: 1; FastEstimator-Train: step: 3600; ce: 0.19960776; loss: 0.039038293; steps/sec: 3.1; FastEstimator-Train: step: 3700; ce: 0.11945578; loss: 0.027948355; steps/sec: 4.25; FastEstimator-Train: step: 3800; ce: 0.23543629; loss: 0.07274181; steps/sec: 4.25; FastEstimator-Train: step: 3900; ce: 0.1563122; loss: 0.042274036; steps/sec: 4.26; FastEstimator-Train: step: 4000; ce: 0.10560348; loss: 0.036032207; steps/sec: 4.26; FastEstimator-Train: step: 4000; epoch: 8; epoch_time(sec): 126.23; Eval Progress: 1/3; Eval Progress: 2/3; steps/sec: 6.62; Eval Progress: 3/3; steps/sec: 8.56; FastEstimator-BestModelSaver: Saved model to /tmp/tmpvj987yxr/model_best_Dice.h5 FastEstimator-Eval: step: 4000; epoch: 8; ce: 0.10399598; Dice: 0.9499806; loss: 0.08048703; max_Dice: 0.9499806; since_best_Dice: 0; FastEstimator-Train: step: 4100; ce: 0.163887; loss: 0.01883065; steps/sec: 3.07; FastEstimator-Train: step: 4200; ce: 0.102094844; loss: 0.023413192; steps/sec: 4.26; FastEstimator-Train: step: 4300; ce: 0.16826805; loss: 0.030300166; steps/sec: 4.26; FastEstimator-Train: step: 4400; ce: 0.15490775; loss: 0.023021162; steps/sec: 4.24; FastEstimator-Train: step: 4500; ce: 0.1905218; loss: 0.0153473625; steps/sec: 4.26; FastEstimator-Train: step: 4500; epoch: 9; epoch_time(sec): 126.52; Eval Progress: 1/3; Eval Progress: 2/3; steps/sec: 8.8; Eval Progress: 3/3; steps/sec: 1.68; FastEstimator-Eval: step: 4500; epoch: 9; ce: 0.12404089; Dice: 0.94300604; loss: 0.10201959; max_Dice: 0.9499806; since_best_Dice: 1; FastEstimator-Train: step: 4600; ce: 0.12044421; loss: 0.017587004; steps/sec: 3.14; FastEstimator-Train: step: 4700; ce: 0.10911618; loss: 0.013906989; steps/sec: 4.25; FastEstimator-Train: step: 4800; ce: 0.12843582; loss: 0.013294442; steps/sec: 4.26; FastEstimator-Train: step: 4900; ce: 0.14869489; loss: 0.015075884; steps/sec: 4.26; FastEstimator-Train: step: 5000; ce: 0.1690086; loss: 0.02366755; steps/sec: 4.26; FastEstimator-Train: step: 5000; epoch: 10; epoch_time(sec): 125.84; Eval Progress: 1/3; Eval Progress: 2/3; steps/sec: 8.96; Eval Progress: 3/3; steps/sec: 9.39; FastEstimator-Eval: step: 5000; epoch: 10; ce: 0.15026438; Dice: 0.93121094; loss: 0.10265809; max_Dice: 0.9499806; since_best_Dice: 2; FastEstimator-Train: step: 5100; ce: 0.1377446; loss: 0.016510364; steps/sec: 3.11; FastEstimator-Train: step: 5200; ce: 0.15856548; loss: 0.012721126; steps/sec: 4.25; FastEstimator-Train: step: 5300; ce: 0.12806118; loss: 0.017488793; steps/sec: 4.25; FastEstimator-Train: step: 5400; ce: 0.21298575; loss: 0.013357449; steps/sec: 4.25; FastEstimator-Train: step: 5500; ce: 0.19698796; loss: 0.020724446; steps/sec: 4.25; FastEstimator-Train: step: 5500; epoch: 11; epoch_time(sec): 126.26;
Eval Progress: 1/3; Eval Progress: 2/3; steps/sec: 6.63; Eval Progress: 3/3; steps/sec: 8.39; FastEstimator-Eval: step: 5500; epoch: 11; ce: 0.16355596; Dice: 0.94106233; loss: 0.11023188; max_Dice: 0.9499806; since_best_Dice: 3; FastEstimator-Train: step: 5600; ce: 0.11141123; loss: 0.012682293; steps/sec: 3.11; FastEstimator-Train: step: 5700; ce: 0.16296203; loss: 0.018117331; steps/sec: 4.25; FastEstimator-Train: step: 5800; ce: 0.15084213; loss: 0.00884895; steps/sec: 4.26; FastEstimator-Train: step: 5900; ce: 0.0955751; loss: 0.016850332; steps/sec: 4.26; FastEstimator-Train: step: 6000; ce: 0.16943866; loss: 0.017093498; steps/sec: 4.26; FastEstimator-Train: step: 6000; epoch: 12; epoch_time(sec): 126.18; Eval Progress: 1/3; Eval Progress: 2/3; steps/sec: 9.09; Eval Progress: 3/3; steps/sec: 7.1; FastEstimator-Eval: step: 6000; epoch: 12; ce: 0.16514257; Dice: 0.939072; loss: 0.101488665; max_Dice: 0.9499806; since_best_Dice: 4; FastEstimator-Train: step: 6100; ce: 0.121002406; loss: 0.024905292; steps/sec: 3.1; FastEstimator-Train: step: 6200; ce: 0.10999095; loss: 0.022950191; steps/sec: 4.25; FastEstimator-Train: step: 6300; ce: 0.096304476; loss: 0.018158548; steps/sec: 4.25; FastEstimator-Train: step: 6400; ce: 0.091410406; loss: 0.033622492; steps/sec: 4.25; FastEstimator-Train: step: 6500; ce: 0.10592766; loss: 0.0124795195; steps/sec: 4.25; FastEstimator-Train: step: 6500; epoch: 13; epoch_time(sec): 126.29; Eval Progress: 1/3; Eval Progress: 2/3; steps/sec: 3.55; Eval Progress: 3/3; steps/sec: 4.39; FastEstimator-BestModelSaver: Saved model to /tmp/tmpvj987yxr/model_best_Dice.h5 FastEstimator-Eval: step: 6500; epoch: 13; ce: 0.11707865; Dice: 0.9503854; loss: 0.08258657; max_Dice: 0.9503854; since_best_Dice: 0; FastEstimator-Train: step: 6600; ce: 0.11463246; loss: 0.012381219; steps/sec: 3.07; FastEstimator-Train: step: 6700; ce: 0.2361474; loss: 0.017297272; steps/sec: 4.25; FastEstimator-Train: step: 6800; ce: 0.1392948; loss: 0.01634121; steps/sec: 4.25; FastEstimator-Train: step: 6900; ce: 0.15834257; loss: 0.016620096; steps/sec: 4.25; FastEstimator-Train: step: 7000; ce: 0.08943112; loss: 0.01452676; steps/sec: 4.25; FastEstimator-Train: step: 7000; epoch: 14; epoch_time(sec): 126.86; Eval Progress: 1/3; Eval Progress: 2/3; steps/sec: 2.59; Eval Progress: 3/3; steps/sec: 3.63; FastEstimator-Eval: step: 7000; epoch: 14; ce: 0.102019; Dice: 0.947197; loss: 0.09485459; max_Dice: 0.9503854; since_best_Dice: 1; FastEstimator-Train: step: 7100; ce: 0.093647905; loss: 0.015946763; steps/sec: 3.08; FastEstimator-Train: step: 7200; ce: 0.13554126; loss: 0.019899167; steps/sec: 4.25; FastEstimator-Train: step: 7300; ce: 0.07730062; loss: 0.011123005; steps/sec: 4.25; FastEstimator-Train: step: 7400; ce: 0.13298267; loss: 0.01565573; steps/sec: 4.26; FastEstimator-Train: step: 7500; ce: 0.087310925; loss: 0.00966887; steps/sec: 4.25; FastEstimator-Train: step: 7500; epoch: 15; epoch_time(sec): 126.43; Eval Progress: 1/3; Eval Progress: 2/3; steps/sec: 8.07; Eval Progress: 3/3; steps/sec: 8.18; FastEstimator-Eval: step: 7500; epoch: 15; ce: 0.11306052; Dice: 0.94702214; loss: 0.10762387; max_Dice: 0.9503854; since_best_Dice: 2; FastEstimator-Train: step: 7600; ce: 0.0804214; loss: 0.010615739; steps/sec: 3.13; FastEstimator-Train: step: 7700; ce: 0.106527194; loss: 0.016999874; steps/sec: 4.26; FastEstimator-Train: step: 7800; ce: 0.08867468; loss: 0.009447395; steps/sec: 4.26; FastEstimator-Train: step: 7900; ce: 0.11922002; loss: 0.008406167; steps/sec: 4.24; FastEstimator-Train: step: 8000; ce: 0.20857453; loss: 0.0071371705; steps/sec: 4.22; FastEstimator-Train: step: 8000; epoch: 16; epoch_time(sec): 126.86; Eval Progress: 1/3; Eval Progress: 2/3; steps/sec: 6.66; Eval Progress: 3/3; steps/sec: 6.94; FastEstimator-Eval: step: 8000; epoch: 16; ce: 0.17731215; Dice: 0.93178856; loss: 0.1303885; max_Dice: 0.9503854; since_best_Dice: 3; FastEstimator-Train: step: 8100; ce: 0.17820936; loss: 0.012737158; steps/sec: 2.77; FastEstimator-Train: step: 8200; ce: 0.08896818; loss: 0.013299987; steps/sec: 4.24; FastEstimator-Train: step: 8300; ce: 0.09162216; loss: 0.009016777; steps/sec: 4.23; FastEstimator-Train: step: 8400; ce: 0.18506084; loss: 0.013894494; steps/sec: 4.24; FastEstimator-Train: step: 8500; ce: 0.07619628; loss: 0.012683237; steps/sec: 4.24; FastEstimator-Train: step: 8500; epoch: 17; epoch_time(sec): 129.86; Eval Progress: 1/3; Eval Progress: 2/3; steps/sec: 7.78; Eval Progress: 3/3; steps/sec: 8.06; FastEstimator-Eval: step: 8500; epoch: 17; ce: 0.13557616; Dice: 0.94524765; loss: 0.12544899; max_Dice: 0.9503854; since_best_Dice: 4; FastEstimator-Train: step: 8600; ce: 0.15562437; loss: 0.014089562; steps/sec: 3.1; FastEstimator-Train: step: 8700; ce: 0.11231899; loss: 0.01911705; steps/sec: 4.25; FastEstimator-Train: step: 8800; ce: 0.095766395; loss: 0.035510726; steps/sec: 4.25; FastEstimator-Train: step: 8900; ce: 0.08149881; loss: 0.014410654; steps/sec: 4.25; FastEstimator-Train: step: 9000; ce: 0.17572197; loss: 0.015565524; steps/sec: 4.26; FastEstimator-Train: step: 9000; epoch: 18; epoch_time(sec): 126.24; Eval Progress: 1/3; Eval Progress: 2/3; steps/sec: 7.53; Eval Progress: 3/3; steps/sec: 7.92; FastEstimator-Eval: step: 9000; epoch: 18; ce: 0.14650795; Dice: 0.89750546; loss: 0.08658847; max_Dice: 0.9503854; since_best_Dice: 5; FastEstimator-Train: step: 9100; ce: 0.111510925; loss: 0.010694086; steps/sec: 3.07; FastEstimator-Train: step: 9200; ce: 0.08624919; loss: 0.016172672; steps/sec: 4.26; FastEstimator-Train: step: 9300; ce: 0.091734245; loss: 0.01361499; steps/sec: 4.26; FastEstimator-Train: step: 9400; ce: 0.117776856; loss: 0.015913276; steps/sec: 4.26; FastEstimator-Train: step: 9500; ce: 0.23866719; loss: 0.010917987; steps/sec: 4.26; FastEstimator-Train: step: 9500; epoch: 19; epoch_time(sec): 126.49; Eval Progress: 1/3; Eval Progress: 2/3; steps/sec: 1.7; Eval Progress: 3/3; steps/sec: 7.66; FastEstimator-Eval: step: 9500; epoch: 19; ce: 0.13534433; Dice: 0.94908464; loss: 0.11581099; max_Dice: 0.9503854; since_best_Dice: 6; FastEstimator-Train: step: 9600; ce: 0.1392692; loss: 0.012704063; steps/sec: 3.1; FastEstimator-Train: step: 9700; ce: 0.15621491; loss: 0.012495002; steps/sec: 4.26; FastEstimator-Train: step: 9800; ce: 0.18249944; loss: 0.01148418; steps/sec: 4.26; FastEstimator-Train: step: 9900; ce: 0.2243041; loss: 0.013589382; steps/sec: 4.27; FastEstimator-Train: step: 10000; ce: 0.15251833; loss: 0.010488838; steps/sec: 4.26; FastEstimator-Train: step: 10000; epoch: 20; epoch_time(sec): 126.09; Eval Progress: 1/3; Eval Progress: 2/3; steps/sec: 5.56; Eval Progress: 3/3; steps/sec: 8.81; FastEstimator-BestModelSaver: Saved model to /tmp/tmpvj987yxr/model_best_Dice.h5 FastEstimator-Eval: step: 10000; epoch: 20; ce: 0.13413922; Dice: 0.9532021; loss: 0.1172003; max_Dice: 0.9532021; since_best_Dice: 0; FastEstimator-BestModelSaver: Restoring model from /tmp/tmpvj987yxr/model_best_Dice.h5 FastEstimator-Finish: step: 10000; model_lr: 1e-04; total_time(sec): 2766.68;
Inferencing¶
Once the model is trained, we can infer it to visualize the generated mask
# get pipeline data
data = pipeline.get_results(mode="eval")
# get network output
network_data = network.transform(data, mode="infer")
image = network_data["image"]
mask = network_data["mask"]
bbox_mask = network_data['box_mask']
prediction = network_data['pred_segment']
2023-01-04 23:46:01.781832: I tensorflow/stream_executor/cuda/cuda_blas.cc:1786] TensorFloat-32 will be used for the matrix multiplication. This will only be logged once.
sample_num = 4
GridDisplay([BatchDisplay(image=image[0:sample_num], title="Input Image"),
BatchDisplay(image=image[0:sample_num], masks=bbox_mask[0:sample_num], title="Bounding Box Mask"),
BatchDisplay(image=image[0:sample_num], masks=prediction[0:sample_num], title="Prediction Mask"),
BatchDisplay(image=image[0:sample_num], masks=mask[0:sample_num], title="Original Pixel Mask"),]).show()

It can be seen that we can use bounding box annotations to accurately perform semantic segmentation even without pixel-level mask annotation. This method can help us reduce annotation cost and time massively.