Tutorial 8: Mode¶
Overview¶
In this tutorial we are going to cover:
Modes¶
The development cycle of a deep learning application can usually be broken into 4 phases: training, evaluation, testing, and inference.
FastEstimator provides 4 corresponding modes: train, eval, test, and infer that allow users to manage each phase independently. Users have the flexibility to construct the Network and Pipeline in different ways for each of those modes. Only a single mode can ever be active at a time, and for each given mode the corresponding graph topology will be computed and executed.
When Modes are Activated¶
- train:
estimator.fit()being called, during training cycle - eval:
estimator.fit()being called, during evaluation cycle - test:
estimator.test()being called - infer:
pipeline.transform(mode="infer")ornetwork.transform(mode="infer")being called (inference will be covered in Tutorial 9)
How to Set Modes¶
From the previous tutorials we already know that Ops define the workflow of Networks and Pipelines, whereas Traces control the training process. All Ops and Traces can be specified to run in one or more modes. Here are all 5 ways to set the modes:
Setting a single mode
Specify the desired mode as string.
Ex: Op(mode="train")Setting multiple modes
Put all desired modes in a tuple or list as an argument.
Ex: Trace(mode=["train", "test"])Setting an exception mode
Prefix a "!" on a mode, and then the object will execute during all modes that are NOT the specified one.
Ex: Op(mode="!train")Setting all modes
Set the mode argument equal to None.
Ex: Trace(mode=None)Using the default mode setting
Don't specify anything in mode argument. DifferentOpsandTraceshave different default mode settings.
Ex:UpdateOp-> default mode: train
Ex:Accuracytrace -> default mode: eval, test
Code Example¶
Let's see come example code and visualize the topology of the corresponding execution graphs for each mode:
import fastestimator as fe
from fastestimator.dataset.data import mnist
from fastestimator.trace.metric import Accuracy
from fastestimator.op.numpyop.univariate import ExpandDims, Minmax, CoarseDropout
from fastestimator.op.tensorop.loss import CrossEntropy
from fastestimator.op.tensorop.model import ModelOp, UpdateOp
from fastestimator.architecture.tensorflow import LeNet
train_data, eval_data = mnist.load_data()
test_data = eval_data.split(0.5)
model = fe.build(model_fn=LeNet, optimizer_fn="adam")
pipeline = fe.Pipeline(train_data=train_data,
eval_data=eval_data,
test_data=test_data,
batch_size=32,
ops=[ExpandDims(inputs="x", outputs="x"), #default mode=None
Minmax(inputs="x", outputs="x_out", mode=None),
CoarseDropout(inputs="x_out", outputs="x_out", mode="train")])
network = fe.Network(ops=[ModelOp(model=model, inputs="x_out", outputs="y_pred"), #default mode=None
CrossEntropy(inputs=("y_pred", "y"), outputs="ce", mode="!infer"),
UpdateOp(model=model, loss_name="ce", mode="train")])
estimator = fe.Estimator(pipeline=pipeline,
network=network,
epochs=2,
traces=Accuracy(true_key="y", pred_key="y_pred")) # default mode=[eval, test]
Train Mode¶
The following figure shows the execution flow for the "train" mode. It has a complete data pipeline including the CoarseDropout data augmentation Op. The data source of the pipeline is "train_data". The Accuracy Trace will not exist in this mode because the default mode of that trace is "eval" and "test".

Eval Mode¶
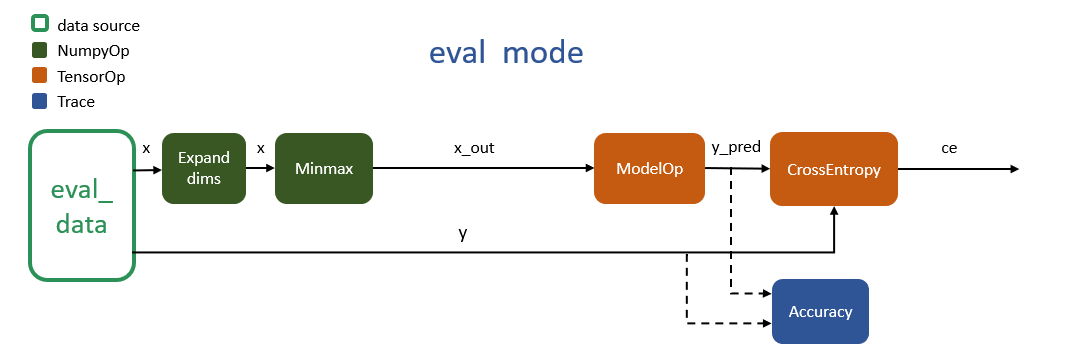
The following figure shows the execution flow for the "eval" mode. The data augmentation block is missing and the pipeline data source is "eval_data". The Accuracy block exist in this mode because of its default trace setting.
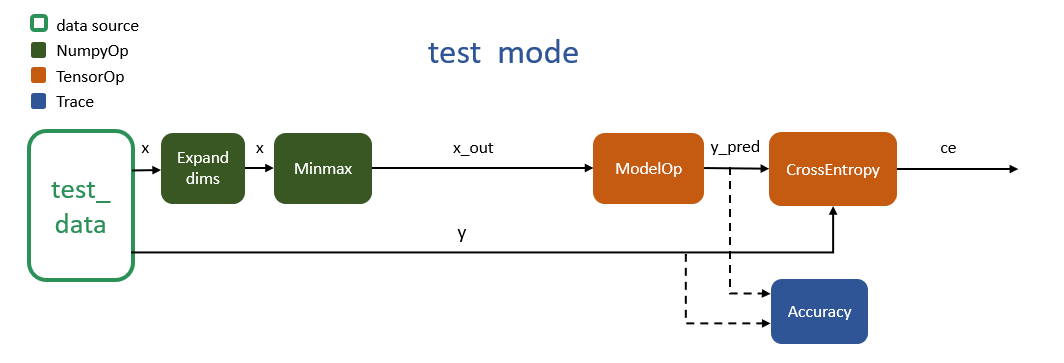
Test Mode¶
Everything in the "test" mode is the same as the "eval" mode, except that the data source of pipeline has switched to "test_data":
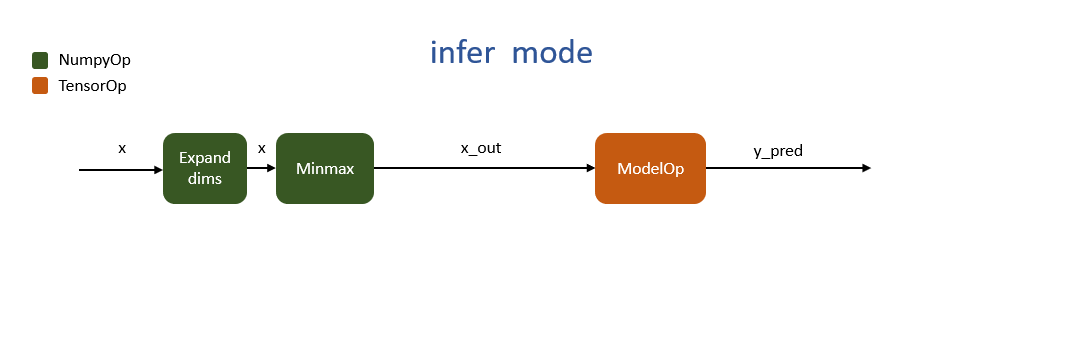
Infer Mode¶
"Infer" mode only has the minimum operations that model inference requires. The data source is not defined yet because input data will not be passed until the inference function is invoked. See Tutorial 9 for more details.