Estimator is the API that manages everything related to the training loop. It combines Pipeline and Network together and provides users with fine-grain control over the training loop. Before we demonstrate different ways to control the training loop let's define a template similar to tutorial 1, but this time we will use a PyTorch model.
import fastestimator as fe
from fastestimator.architecture.pytorch import LeNet
from fastestimator.dataset.data import mnist
from fastestimator.op.numpyop.univariate import ExpandDims, Minmax
from fastestimator.op.tensorop.loss import CrossEntropy
from fastestimator.op.tensorop.model import ModelOp, UpdateOp
import tempfile
def get_estimator(log_steps=100, monitor_names=None, use_trace=False, train_steps_per_epoch=None, epochs=2):
# step 1
train_data, eval_data = mnist.load_data()
test_data = eval_data.split(0.5)
pipeline = fe.Pipeline(train_data=train_data,
eval_data=eval_data,
test_data=test_data,
batch_size=32,
ops=[ExpandDims(inputs="x", outputs="x", axis=0), Minmax(inputs="x", outputs="x")])
# step 2
model = fe.build(model_fn=LeNet, optimizer_fn="adam", model_name="LeNet")
network = fe.Network(ops=[
ModelOp(model=model, inputs="x", outputs="y_pred"),
CrossEntropy(inputs=("y_pred", "y"), outputs="ce"),
CrossEntropy(inputs=("y_pred", "y"), outputs="ce1"),
UpdateOp(model=model, loss_name="ce")
])
# step 3
traces = None
if use_trace:
traces = [Accuracy(true_key="y", pred_key="y_pred"),
BestModelSaver(model=model, save_dir=tempfile.mkdtemp(), metric="accuracy", save_best_mode="max")]
estimator = fe.Estimator(pipeline=pipeline,
network=network,
epochs=epochs,
traces=traces,
train_steps_per_epoch=train_steps_per_epoch,
log_steps=log_steps,
monitor_names=monitor_names)
return estimator
Let's train our model using the default Estimator arguments:
est = get_estimator()
est.fit()
______ __ ______ __ _ __
/ ____/___ ______/ /_/ ____/____/ /_(_)___ ___ ____ _/ /_____ _____
/ /_ / __ `/ ___/ __/ __/ / ___/ __/ / __ `__ \/ __ `/ __/ __ \/ ___/
/ __/ / /_/ (__ ) /_/ /___(__ ) /_/ / / / / / / /_/ / /_/ /_/ / /
/_/ \__,_/____/\__/_____/____/\__/_/_/ /_/ /_/\__,_/\__/\____/_/
FastEstimator-Warn: No ModelSaver Trace detected. Models will not be saved.
FastEstimator-Start: step: 1; num_device: 1; logging_interval: 100;
FastEstimator-Train: step: 1; ce: 2.295395;
FastEstimator-Train: step: 100; ce: 0.8820845; steps/sec: 320.73;
FastEstimator-Train: step: 200; ce: 0.37291068; steps/sec: 319.45;
FastEstimator-Train: step: 300; ce: 0.06651708; steps/sec: 309.93;
FastEstimator-Train: step: 400; ce: 0.21876352; steps/sec: 309.78;
FastEstimator-Train: step: 500; ce: 0.08403016; steps/sec: 309.19;
FastEstimator-Train: step: 600; ce: 0.35541984; steps/sec: 308.78;
FastEstimator-Train: step: 700; ce: 0.06964149; steps/sec: 300.41;
FastEstimator-Train: step: 800; ce: 0.13983297; steps/sec: 309.22;
FastEstimator-Train: step: 900; ce: 0.037845124; steps/sec: 312.94;
FastEstimator-Train: step: 1000; ce: 0.13029681; steps/sec: 316.27;
FastEstimator-Train: step: 1100; ce: 0.022184685; steps/sec: 312.62;
FastEstimator-Train: step: 1200; ce: 0.039918672; steps/sec: 315.24;
FastEstimator-Train: step: 1300; ce: 0.05553157; steps/sec: 313.87;
FastEstimator-Train: step: 1400; ce: 0.0021400168; steps/sec: 343.22;
FastEstimator-Train: step: 1500; ce: 0.07833527; steps/sec: 336.56;
FastEstimator-Train: step: 1600; ce: 0.09543828; steps/sec: 324.81;
FastEstimator-Train: step: 1700; ce: 0.14825855; steps/sec: 318.52;
FastEstimator-Train: step: 1800; ce: 0.01032154; steps/sec: 322.95;
FastEstimator-Train: step: 1875; epoch: 1; epoch_time: 5.99 sec;
FastEstimator-Eval: step: 1875; epoch: 1; ce: 0.06244616;
FastEstimator-Train: step: 1900; ce: 0.015050106; steps/sec: 263.35;
FastEstimator-Train: step: 2000; ce: 0.003486173; steps/sec: 295.2;
FastEstimator-Train: step: 2100; ce: 0.06401425; steps/sec: 310.64;
FastEstimator-Train: step: 2200; ce: 0.008118075; steps/sec: 297.08;
FastEstimator-Train: step: 2300; ce: 0.05136842; steps/sec: 289.31;
FastEstimator-Train: step: 2400; ce: 0.10011706; steps/sec: 290.44;
FastEstimator-Train: step: 2500; ce: 0.007041894; steps/sec: 287.94;
FastEstimator-Train: step: 2600; ce: 0.041005336; steps/sec: 301.21;
FastEstimator-Train: step: 2700; ce: 0.0023359149; steps/sec: 311.66;
FastEstimator-Train: step: 2800; ce: 0.034970395; steps/sec: 278.47;
FastEstimator-Train: step: 2900; ce: 0.024958389; steps/sec: 294.08;
FastEstimator-Train: step: 3000; ce: 0.0038549905; steps/sec: 291.1;
FastEstimator-Train: step: 3100; ce: 0.14712071; steps/sec: 311.67;
FastEstimator-Train: step: 3200; ce: 0.14290668; steps/sec: 316.4;
FastEstimator-Train: step: 3300; ce: 0.34252185; steps/sec: 304.94;
FastEstimator-Train: step: 3400; ce: 0.0059393854; steps/sec: 297.43;
FastEstimator-Train: step: 3500; ce: 0.2493474; steps/sec: 323.9;
FastEstimator-Train: step: 3600; ce: 0.004362625; steps/sec: 322.78;
FastEstimator-Train: step: 3700; ce: 0.0058870725; steps/sec: 296.6;
FastEstimator-Train: step: 3750; epoch: 2; epoch_time: 6.31 sec;
FastEstimator-Eval: step: 3750; epoch: 2; ce: 0.053535815;
FastEstimator-Finish: step: 3750; total_time: 14.81 sec; LeNet_lr: 0.001;
Estimator API¶
Reduce the number of training steps per epoch¶
In general, one epoch of training means that every element in the training dataset will be visited exactly one time. If evaluation data is available, evaluation happens after every epoch by default. Consider the following two scenarios:
- The training dataset is very large such that evaluation needs to happen multiple times during one epoch.
- Different training datasets are being used for different epochs, but the number of training steps should be consistent between each epoch.
One easy solution to the above scenarios is to limit the number of training steps per epoch. For example, if we want to train for only 300 steps per epoch, with training lasting for 4 epochs (1200 steps total), we would do the following:
est = get_estimator(train_steps_per_epoch=300, epochs=4)
est.fit()
______ __ ______ __ _ __
/ ____/___ ______/ /_/ ____/____/ /_(_)___ ___ ____ _/ /_____ _____
/ /_ / __ `/ ___/ __/ __/ / ___/ __/ / __ `__ \/ __ `/ __/ __ \/ ___/
/ __/ / /_/ (__ ) /_/ /___(__ ) /_/ / / / / / / /_/ / /_/ /_/ / /
/_/ \__,_/____/\__/_____/____/\__/_/_/ /_/ /_/\__,_/\__/\____/_/
FastEstimator-Warn: No ModelSaver Trace detected. Models will not be saved.
FastEstimator-Start: step: 1; num_device: 1; logging_interval: 100;
FastEstimator-Train: step: 1; ce: 2.311253;
FastEstimator-Train: step: 100; ce: 0.66614795; steps/sec: 274.95;
FastEstimator-Train: step: 200; ce: 0.46526748; steps/sec: 309.99;
FastEstimator-Train: step: 300; ce: 0.11188476; steps/sec: 336.57;
FastEstimator-Train: step: 300; epoch: 1; epoch_time: 0.99 sec;
FastEstimator-Eval: step: 300; epoch: 1; ce: 0.17669827;
FastEstimator-Train: step: 400; ce: 0.2917202; steps/sec: 332.81;
FastEstimator-Train: step: 500; ce: 0.047290877; steps/sec: 323.56;
FastEstimator-Train: step: 600; ce: 0.053344093; steps/sec: 315.52;
FastEstimator-Train: step: 600; epoch: 2; epoch_time: 0.93 sec;
FastEstimator-Eval: step: 600; epoch: 2; ce: 0.11926653;
FastEstimator-Train: step: 700; ce: 0.06439964; steps/sec: 300.28;
FastEstimator-Train: step: 800; ce: 0.026502458; steps/sec: 300.13;
FastEstimator-Train: step: 900; ce: 0.34012184; steps/sec: 303.24;
FastEstimator-Train: step: 900; epoch: 3; epoch_time: 1.0 sec;
FastEstimator-Eval: step: 900; epoch: 3; ce: 0.075678065;
FastEstimator-Train: step: 1000; ce: 0.044892587; steps/sec: 285.03;
FastEstimator-Train: step: 1100; ce: 0.037321247; steps/sec: 293.51;
FastEstimator-Train: step: 1200; ce: 0.011022182; steps/sec: 294.91;
FastEstimator-Train: step: 1200; epoch: 4; epoch_time: 1.03 sec;
FastEstimator-Eval: step: 1200; epoch: 4; ce: 0.06031439;
FastEstimator-Finish: step: 1200; total_time: 9.29 sec; LeNet_lr: 0.001;
Reduce the number of evaluation steps per epoch¶
One may need to reduce the number of evaluation steps for debugging purpose. This can be easily done by setting the eval_steps_per_epoch argument in Estimator.
Change logging behavior¶
When the number of training epochs is large, the log can become verbose. You can change the logging behavior by choosing one of following options:
- set
log_stepstoNoneif you do not want to see any training logs printed. - set
log_stepsto 0 if you only wish to see the evaluation logs. - set
log_stepsto some integer 'x' if you want training logs to be printed every 'x' steps.
Let's set the log_steps to 0:
est = get_estimator(train_steps_per_epoch=300, epochs=4, log_steps=0)
est.fit()
______ __ ______ __ _ __
/ ____/___ ______/ /_/ ____/____/ /_(_)___ ___ ____ _/ /_____ _____
/ /_ / __ `/ ___/ __/ __/ / ___/ __/ / __ `__ \/ __ `/ __/ __ \/ ___/
/ __/ / /_/ (__ ) /_/ /___(__ ) /_/ / / / / / / /_/ / /_/ /_/ / /
/_/ \__,_/____/\__/_____/____/\__/_/_/ /_/ /_/\__,_/\__/\____/_/
FastEstimator-Warn: No ModelSaver Trace detected. Models will not be saved.
FastEstimator-Start: step: 1; num_device: 1; logging_interval: 0;
FastEstimator-Eval: step: 300; epoch: 1; ce: 0.16322972;
FastEstimator-Eval: step: 600; epoch: 2; ce: 0.10085282;
FastEstimator-Eval: step: 900; epoch: 3; ce: 0.08177921;
FastEstimator-Eval: step: 1200; epoch: 4; ce: 0.0629242;
FastEstimator-Finish: step: 1200; total_time: 9.14 sec; LeNet_lr: 0.001;
Monitor intermediate results¶
You might have noticed that in our example Network there is an op: CrossEntropy(inputs=("y_pred", "y") outputs="ce1"). However, the ce1 never shows up in the training log above. This is because FastEstimator identifies and filters out unused variables to reduce unnecessary communication between the GPU and CPU. On the contrary, ce shows up in the log because by default we log all loss values that are used to update models.
But what if we want to see the value of ce1 throughout training?
Easy: just add ce1 to monitor_names in Estimator.
est = get_estimator(train_steps_per_epoch=300, epochs=4, log_steps=150, monitor_names="ce1")
est.fit()
______ __ ______ __ _ __
/ ____/___ ______/ /_/ ____/____/ /_(_)___ ___ ____ _/ /_____ _____
/ /_ / __ `/ ___/ __/ __/ / ___/ __/ / __ `__ \/ __ `/ __/ __ \/ ___/
/ __/ / /_/ (__ ) /_/ /___(__ ) /_/ / / / / / / /_/ / /_/ /_/ / /
/_/ \__,_/____/\__/_____/____/\__/_/_/ /_/ /_/\__,_/\__/\____/_/
FastEstimator-Warn: No ModelSaver Trace detected. Models will not be saved.
FastEstimator-Start: step: 1; num_device: 1; logging_interval: 150;
FastEstimator-Train: step: 1; ce: 2.2930875; ce1: 2.2930875;
FastEstimator-Train: step: 150; ce: 0.29343712; ce1: 0.29343712; steps/sec: 292.71;
FastEstimator-Train: step: 300; ce: 0.37277684; ce1: 0.37277684; steps/sec: 284.64;
FastEstimator-Train: step: 300; epoch: 1; epoch_time: 1.05 sec;
FastEstimator-Eval: step: 300; epoch: 1; ce: 0.21327984; ce1: 0.21327984;
FastEstimator-Train: step: 450; ce: 0.3631664; ce1: 0.3631664; steps/sec: 277.43;
FastEstimator-Train: step: 600; ce: 0.2957161; ce1: 0.2957161; steps/sec: 304.11;
FastEstimator-Train: step: 600; epoch: 2; epoch_time: 1.03 sec;
FastEstimator-Eval: step: 600; epoch: 2; ce: 0.10858435; ce1: 0.10858435;
FastEstimator-Train: step: 750; ce: 0.1193773; ce1: 0.1193773; steps/sec: 301.03;
FastEstimator-Train: step: 900; ce: 0.05718822; ce1: 0.05718822; steps/sec: 294.92;
FastEstimator-Train: step: 900; epoch: 3; epoch_time: 1.01 sec;
FastEstimator-Eval: step: 900; epoch: 3; ce: 0.093043245; ce1: 0.093043245;
FastEstimator-Train: step: 1050; ce: 0.102503434; ce1: 0.102503434; steps/sec: 297.27;
FastEstimator-Train: step: 1200; ce: 0.011180073; ce1: 0.011180073; steps/sec: 296.55;
FastEstimator-Train: step: 1200; epoch: 4; epoch_time: 1.01 sec;
FastEstimator-Eval: step: 1200; epoch: 4; ce: 0.082674295; ce1: 0.082674295;
FastEstimator-Finish: step: 1200; total_time: 9.62 sec; LeNet_lr: 0.001;
As we can see, both ce and ce1 showed up in the log above. Unsurprisingly, their values are identical because because they have the same inputs and forward function.
Trace¶
Concept¶
Now you might be thinking: 'changing logging behavior and monitoring extra keys is cool, but where is the fine-grained access to the training loop?'
The answer is Trace. Trace is a module that can offer you access to different training stages and allow you "do stuff" with them. Here are some examples of what a Trace can do:
- print any training data at any training step
- write results to a file during training
- change learning rate based on some loss conditions
- calculate any metrics
- order you a pizza after training ends
- ...
So what are the different training stages? They are:
- Beginning of training
- Beginning of epoch
- Beginning of batch
- End of batch
- End of epoch
- End of training
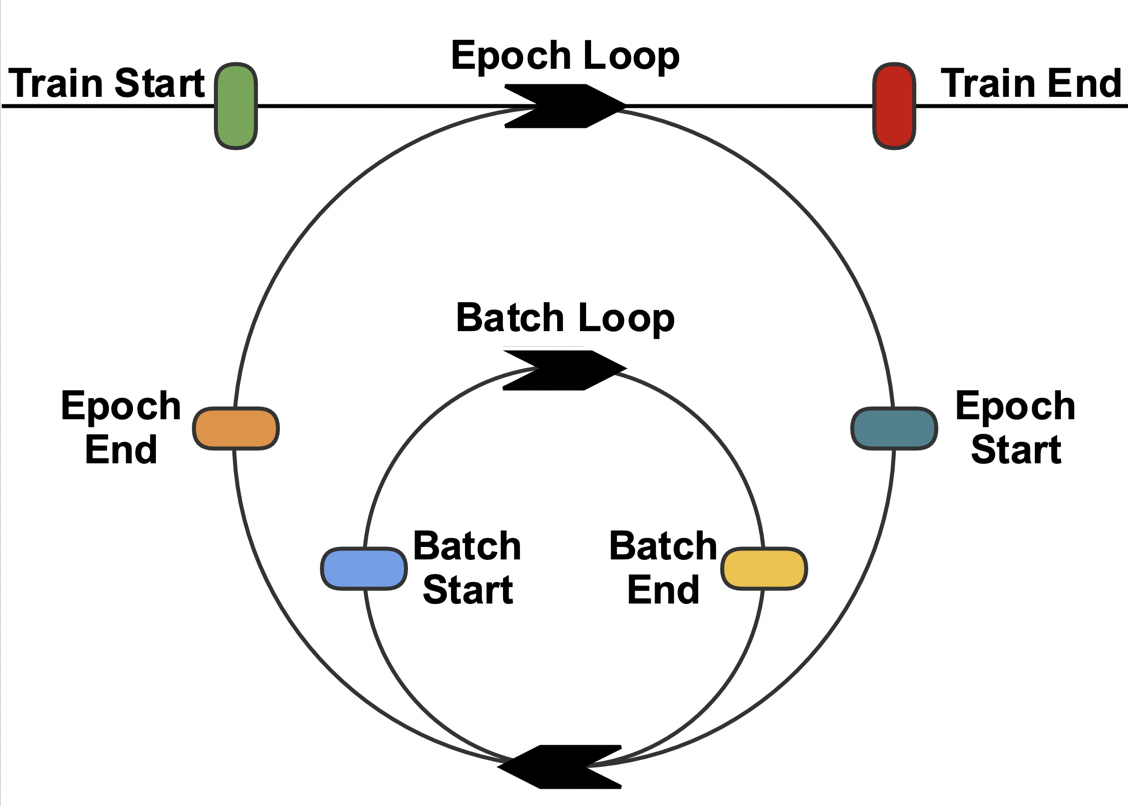
As we can see from the illustration above, the training process is essentially a nested combination of batch loops and epoch loops. Over the course of training, Trace places 6 different "road blocks" for you to leverage.
Structure¶
If you are familiar with Keras, you will notice that the structure of Trace is very similar to the Callback in keras. Despite the structural similarity, Trace gives you a lot more flexibility which we will talk about in depth in advanced tutorial 4. Implementation-wise, Trace is a python class with the following structure:
class Trace:
def __init__(self, inputs=None, outputs=None, mode=None):
self.inputs = inputs
self.outputs = outputs
self.mode = mode
def on_begin(self, data):
"""Runs once at the beginning of training"""
def on_epoch_begin(self, data):
"""Runs at the beginning of each epoch"""
def on_batch_begin(self, data):
"""Runs at the beginning of each batch"""
def on_batch_end(self, data):
"""Runs at the end of each batch"""
def on_epoch_end(self, data):
"""Runs at the end of each epoch"""
def on_end(self, data):
"""Runs once at the end training"""
Given the structure, users can customize their own functions at different stages and insert them into the training loop. We will leave the customization of Traces to the advanced tutorial. For now, let's use some pre-built Traces from FastEstimator.
During the training loop in our earlier example, we want 2 things to happen:
- Save the model weights if the evaluation loss is the best we have seen so far
- Calculate the model accuracy during evaluation
from fastestimator.trace.io import BestModelSaver
from fastestimator.trace.metric import Accuracy
est = get_estimator(use_trace=True)
est.fit()
______ __ ______ __ _ __
/ ____/___ ______/ /_/ ____/____/ /_(_)___ ___ ____ _/ /_____ _____
/ /_ / __ `/ ___/ __/ __/ / ___/ __/ / __ `__ \/ __ `/ __/ __ \/ ___/
/ __/ / /_/ (__ ) /_/ /___(__ ) /_/ / / / / / / /_/ / /_/ /_/ / /
/_/ \__,_/____/\__/_____/____/\__/_/_/ /_/ /_/\__,_/\__/\____/_/
FastEstimator-Start: step: 1; num_device: 1; logging_interval: 100;
FastEstimator-Train: step: 1; ce: 2.303516;
FastEstimator-Train: step: 100; ce: 1.004676; steps/sec: 286.36;
FastEstimator-Train: step: 200; ce: 0.49630624; steps/sec: 286.83;
FastEstimator-Train: step: 300; ce: 0.12231735; steps/sec: 291.9;
FastEstimator-Train: step: 400; ce: 0.14592598; steps/sec: 315.7;
FastEstimator-Train: step: 500; ce: 0.25857; steps/sec: 326.27;
FastEstimator-Train: step: 600; ce: 0.13771628; steps/sec: 331.77;
FastEstimator-Train: step: 700; ce: 0.38054478; steps/sec: 301.89;
FastEstimator-Train: step: 800; ce: 0.07086247; steps/sec: 291.58;
FastEstimator-Train: step: 900; ce: 0.16959156; steps/sec: 308.7;
FastEstimator-Train: step: 1000; ce: 0.021332668; steps/sec: 324.17;
FastEstimator-Train: step: 1100; ce: 0.055990797; steps/sec: 287.57;
FastEstimator-Train: step: 1200; ce: 0.2849428; steps/sec: 292.77;
FastEstimator-Train: step: 1300; ce: 0.20509654; steps/sec: 288.14;
FastEstimator-Train: step: 1400; ce: 0.08241908; steps/sec: 321.32;
FastEstimator-Train: step: 1500; ce: 0.024668839; steps/sec: 320.73;
FastEstimator-Train: step: 1600; ce: 0.01093893; steps/sec: 325.12;
FastEstimator-Train: step: 1700; ce: 0.012216274; steps/sec: 330.77;
FastEstimator-Train: step: 1800; ce: 0.01524183; steps/sec: 328.2;
FastEstimator-Train: step: 1875; epoch: 1; epoch_time: 6.15 sec;
FastEstimator-BestModelSaver: Saved model to /tmp/tmplhuyv721/LeNet_best_accuracy.pt
FastEstimator-Eval: step: 1875; epoch: 1; ce: 0.048887283; accuracy: 0.9814; since_best_accuracy: 0; max_accuracy: 0.9814;
FastEstimator-Train: step: 1900; ce: 0.0056912354; steps/sec: 267.68;
FastEstimator-Train: step: 2000; ce: 0.06863687; steps/sec: 312.62;
FastEstimator-Train: step: 2100; ce: 0.071683794; steps/sec: 319.51;
FastEstimator-Train: step: 2200; ce: 0.023103738; steps/sec: 313.75;
FastEstimator-Train: step: 2300; ce: 0.011231604; steps/sec: 315.5;
FastEstimator-Train: step: 2400; ce: 0.17630634; steps/sec: 310.87;
FastEstimator-Train: step: 2500; ce: 0.01526911; steps/sec: 315.78;
FastEstimator-Train: step: 2600; ce: 0.06935612; steps/sec: 310.69;
FastEstimator-Train: step: 2700; ce: 0.14090665; steps/sec: 308.39;
FastEstimator-Train: step: 2800; ce: 0.0023762842; steps/sec: 309.23;
FastEstimator-Train: step: 2900; ce: 0.025511805; steps/sec: 309.84;
FastEstimator-Train: step: 3000; ce: 0.094952986; steps/sec: 318.57;
FastEstimator-Train: step: 3100; ce: 0.011754904; steps/sec: 299.48;
FastEstimator-Train: step: 3200; ce: 0.033963054; steps/sec: 303.24;
FastEstimator-Train: step: 3300; ce: 0.013373202; steps/sec: 317.35;
FastEstimator-Train: step: 3400; ce: 0.064900294; steps/sec: 295.58;
FastEstimator-Train: step: 3500; ce: 0.29719537; steps/sec: 307.13;
FastEstimator-Train: step: 3600; ce: 0.185368; steps/sec: 307.28;
FastEstimator-Train: step: 3700; ce: 0.005988597; steps/sec: 278.04;
FastEstimator-Train: step: 3750; epoch: 2; epoch_time: 6.19 sec;
FastEstimator-BestModelSaver: Saved model to /tmp/tmplhuyv721/LeNet_best_accuracy.pt
FastEstimator-Eval: step: 3750; epoch: 2; ce: 0.03341377; accuracy: 0.9896; since_best_accuracy: 0; max_accuracy: 0.9896;
FastEstimator-Finish: step: 3750; total_time: 14.96 sec; LeNet_lr: 0.001;
As we can see from the log, the model is saved in a predefined location and the accuracy is displayed during evaluation.
Model Testing¶
Sometimes you have a separate testing dataset other than training and evaluation data. If you want to evalate the model metrics on test data, you can simply call:
est.test()
FastEstimator-Test: step: 3750; epoch: 2; accuracy: 0.9894;
This will feed all of your test dataset through the Pipeline and Network, and finally execute the traces (in our case, compute accuracy) just like during the training.